This weekend I ran the same 20 coding tasks against 16 different LLMs. The most expensive model scored 98.8%. An open-weights model I can self-host scored 94.8%.
The gap is 4%. We should talk about what that means.
The problem with public benchmarks
SWE-bench is the gold standard for evaluating coding AI. It takes real issues from open-source Python repos, gives them to a model, and checks if the patch passes the tests. Impressive in principle. But there are problems.
A paper called "The SWE-Bench Illusion" found evidence that models may be memorising solutions rather than reasoning about them. An OpenAI audit found flawed tests in 59.4% of the problems they checked. And most critically for me: it's all Python. I don't write Python. My entire stack is TypeScript.
SWE-bench tells me which model is best at fixing bugs in Django. It tells me nothing about which model can write a Hono route with Zod validation, fix a race condition in a Mongoose query, or generate a Docker Swarm service spec – which is what I actually do every day to continue the development of Magic Pages backend infrastructure.
So I built my own.
The benchmark
Magic Pages is a managed Ghost hosting platform – 1,300+ sites, Docker Swarm infrastructure, TypeScript everywhere. When I evaluate coding AI, I need to know: can it do my work?
I built a harness with 20 tasks across 7 categories, all modelled on our actual development patterns:
- API endpoints: Hono routes with three-layer architecture, Zod validation, auth middleware
- Bug fixes: based on real issues from our GitHub repo: auth failures, race conditions, webhook idempotency
- Library utilities: DNS validators, Ghost API clients, DKIM validators, currency formatters
- Docker/infrastructure: multi-stage Dockerfiles, Compose configs, Swarm service specs
- Planning: bug investigation reports, feature breakdowns, migration strategies
- React: data-fetching components with sorting and filtering
- Database: MongoDB aggregation pipelines
Each task has a synthetic codebase (to avoid training data contamination), a prompt describing the work, and a hidden test suite that evaluates the result. The model never sees the tests – it works from the spec alone, just like a developer would.
The tasks I provide aren't random open-source issues. The auth bypass task is based on a real issue we had in the postMessage authentication between a Ghost site and our customer portal. The webhook idempotency task comes from a real production incident where Paddle sent a webhook twice and we created a site twice due to that. The Swarm spec generator mirrors how we actually deploy Ghost instances.
If you want to create your own benchmark, I have uploaded the harness to Github:
The results
Here's what these 20 tasks across 16 models looks like:
| # | Model | Score |
|---|---|---|
| 1 | Claude Opus 4.6 | 98.8% |
| 2 | GLM-5.1 | 98.0% |
| 3 | GPT-5.3 Codex | 97.7% |
| 4 | GLM-4.7 | 96.7% |
| 5 | MiniMax M2.5 | 96.1% |
| 6 | Qwen 3.5 122B | 95.1% |
| 7 | Qwen3-Coder-Next | 94.8% |
| 8 | Claude Sonnet 4.6 | 93.4% |
| 9 | Qwen 3.5 397B | 93.2% |
| 10 | DeepSeek V3.2 | 92.8% |
| 11 | Kimi K2.5 | 92.7% |
| 12 | Devstral Small | 92.5% |
| 13 | MiniMax M2.7 | 92.0% |
| 14 | Qwen3-Coder-30B-A3B-Instruct | 89.2% |
| 15 | Mistral Large 3 | 87.9% |
| 16 | Devstral 2 | 82.7% |
The top 13 models all score above 92%. All of them get 100% on bug fixes. All of them write working Ghost API clients, DNS validators, Docker Compose configs.
The model I care most about is #7: Qwen3-Coder-Next. Not because it's the best, but because it's the best one I can run locally – and that question became urgent when my Claude Code subscription started hitting rate limits mid-session. But more on that in a moment.
The entire gap between #1 and #7 comes down to one task: a Hono CRUD endpoint. Opus wires up the auth middleware correctly first try. Qwen3-Coder-Next imports it but doesn't call it.
The gap that isn't
I gave Qwen its own broken code back along with the test output. It fixed the middleware issue in a single iteration. The error was unambiguous – expected 401, got 500 – and it understood immediately what had gone wrong.
In real development, my coding assistants are always instructed to run linting and tests before they're done. The self-correction loop isn't a workaround – it's just how agentic coding works.
On single-shot tasks, Opus leads. On iterative agentic workflows – the way any serious engineering workflow actually runs – the top 13 models are functionally equivalent on my stack. The gaps close when you add a test-and-fix loop. Which you should have anyway.
What does vary is speed and cost.
Claude Opus 4.6 averaged 62 seconds per task. I ran the benchmark using my Claude Code Max plan, which costs $200/month.
GLM-5.1 averaged 258 seconds – their API is clearly under significant load right now. GLM models are tested via z.ai's coding plan at $30/month. Strong results, but the latency is painful. So is the fact that everything is sent to Chinese data centres running inference for me.
Qwen3-Coder-Next averaged 53 seconds per task and is fully open-weights under Apache 2.0. There's no API subscription required – and it's small enough to selfhost it in a meaningful way.
One notable mention: Devstral Small from Mistral, the EU-based AI company. Fast, compact, and 92.5%. Worth watching. Interestingly, its larger sibling Devstral 2 finishes last at 82.7% – a reminder that bigger doesn't always mean better on a specific stack.
Why I'm looking at Qwen3-Coder-Next specifically
This whole rabbit hole started with my Claude Code subscription (the $200/month one) hitting its usage limits mid-session. Not once – regularly. I'd be in the middle of a complex refactoring task, and the model would throttle with API Error: Rate Limit Reached. What the hell? My actual limits were far from being used:
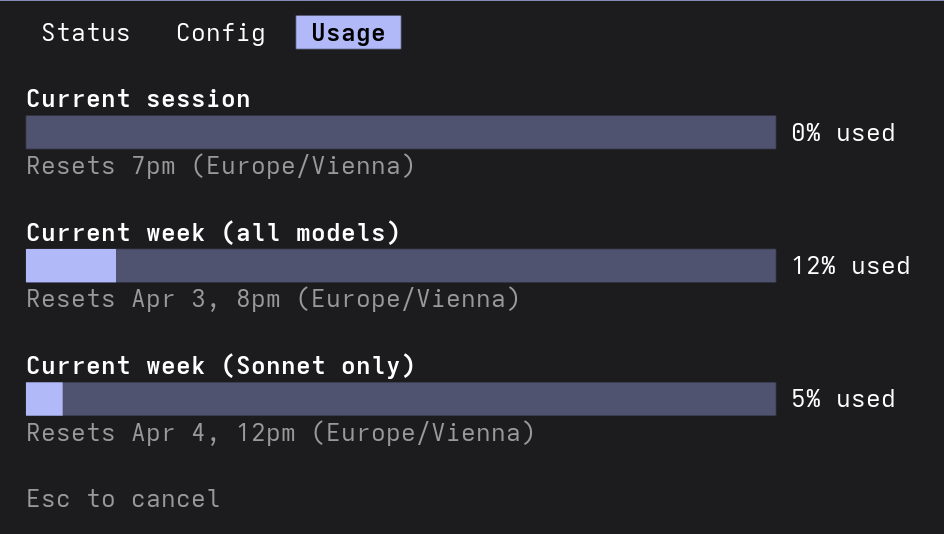
At $200/month, getting these arbitrary rate limit errors is frustrating. And a quick glance at Reddit revealed that I am not the only one.
It made me ask a question I have asked myself several times before: do I actually need a proprietary API for this? And this time, the answer turns out to be quite different.
After a weekend of research and benchmarking, I landed on Qwen3-Coder-Next. It's a mixture-of-experts architecture – 80B total parameters, but only 3B active per token. That's what makes it fast and memory-efficient. At Q4 quantisation it fits in roughly 30GB of VRAM. With context overhead, 64GB total is enough to run it properly.
Running locally means no usage limits, no per-token billing, no latency to a remote server, and – for a company that builds software for other businesses – your code never leaves the building. The hardware cost is offset by Austrian business tax treatment for capital investments, bringing the real cost down to a few months of the subscription that started this whole investigation.
So, do we need proprietary coding LLMs?
The honest answer: it depends on what you mean by "need."
If you need the absolute best single-shot performance, Claude Opus 4.6 is still #1. The difference is real, even if it's small. For complex architectural decisions or getting things right without any feedback loop, Opus has a genuine edge – at least among fully open-weights models you can actually run yourself.
But "the absolute best" is frequently the enemy of "good enough." Every model in my list can fix real production bugs, write typed API clients with proper error handling, generate valid Docker infrastructure, plan feature implementations, and build React components with data fetching. The gaps disappear with proper feedback loops.
The question isn't whether open-weights models can code. They can. The question is whether that last 4% of first-attempt accuracy is worth the vendor dependency, the ongoing subscription cost, and the privacy tradeoff of sending your codebase to a third-party API.
For Magic Pages – a company with a specific, well-understood TypeScript stack – the answer is increasingly no.
When a model scores 94.8% on your actual tasks, self-corrects in one iteration, runs at 30GB VRAM, generates 100+ tokens per second locally, and keeps your code private: the argument for $200/month and a 4% edge gets very, very thin.
I'm not saying proprietary models are dead. I'm saying the edge is slim and getting slimmer. For specific, well-defined stacks – the kind most small companies have – open-weights models are already good enough. And "good enough" on your own hardware, with your data staying local, at zero marginal cost, is a genuinely different proposition from six months ago.