
You know that feeling of wanting to change something that's running perfectly? Well, I do. But quite honestly, this is not that kind of a story.
It's the story of not wanting to change something, but realising that it might be for the better. It's the story of taking a step back.
So let's do just that. Let's take a step back and have a look at Magic Pages' infrastructure and how it developed.
Docker
Back in early 2023, the idea was simple. Let's just host a bunch of Ghost sites. There was no ambition of turning Magic Pages into a fully-fledged managed Ghost hosting provider. Just...a bunch of sites.
The infrastructure was fairly easy: A 64GB RAM dedicated server, running a bunch of Docker containers. Paired with a small VPS that served as an ingress – basically distributing requests to the respective sites.
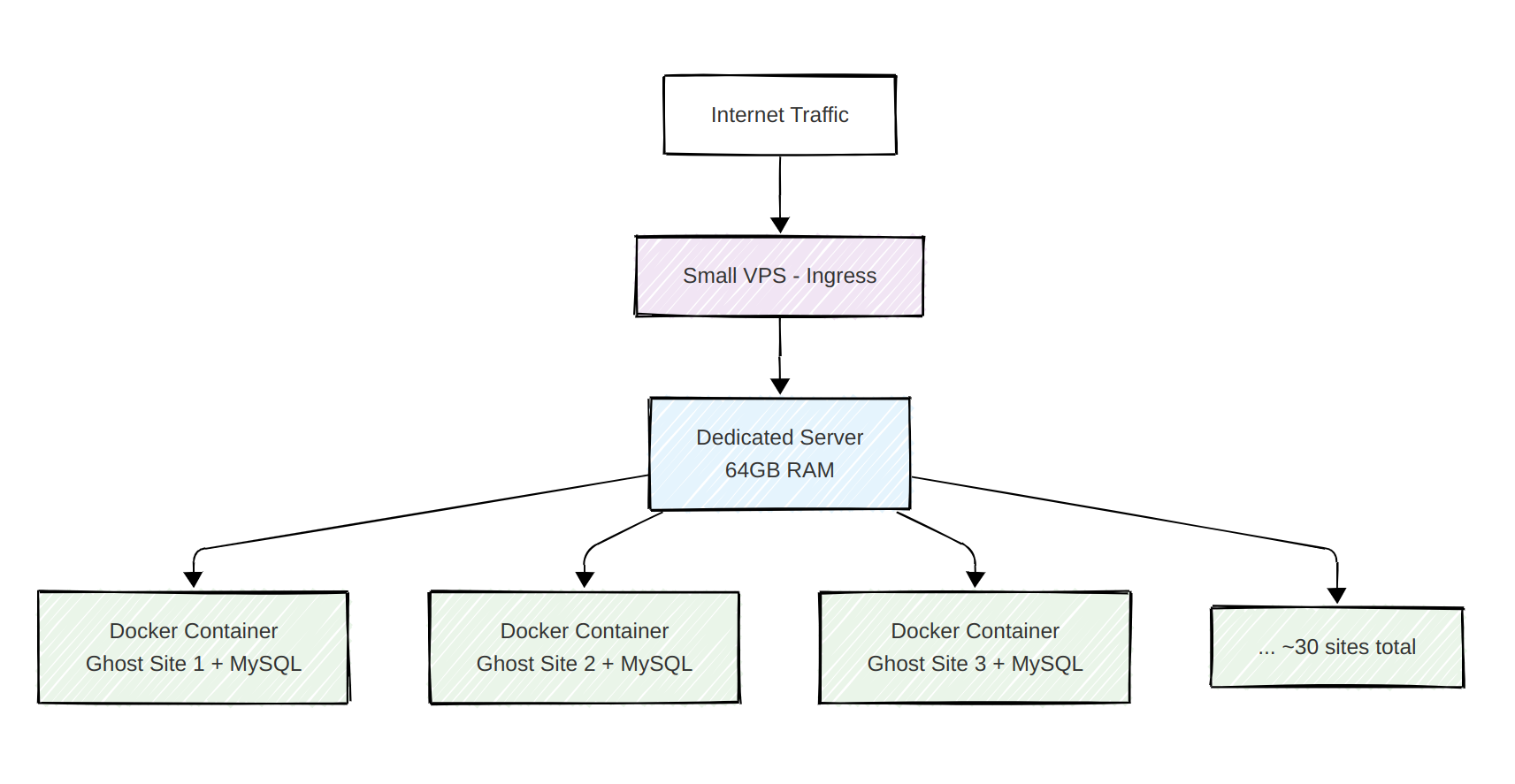
This worked brilliantly for the 30ish sites I hosted. That was the capacity of the lifetime pre-sale I did back then. When it was set up, I didn't actually want to scale it further. I thought that this was a great base for creating a custom Ghost development agency on top of it.
But...the best thing that could happen to an entrepreneur happened: word of mouth. My customers shared about their experience with Magic Pages, and by mid 2023, I realised that there might be potential.
I opened up sales, did a bit of promotion – and by the end of 2023, the single dedicated server was at capacity. Whoopsie.
Docker Swarm
So, what's next? Being familiar with Docker, I turned to Docker Swarm. Essentially, hooking up multiple servers to create a "swarm". They could interact and schedule workload with each other, and simply provide room for scaling (by simply adding another server to the swarm).
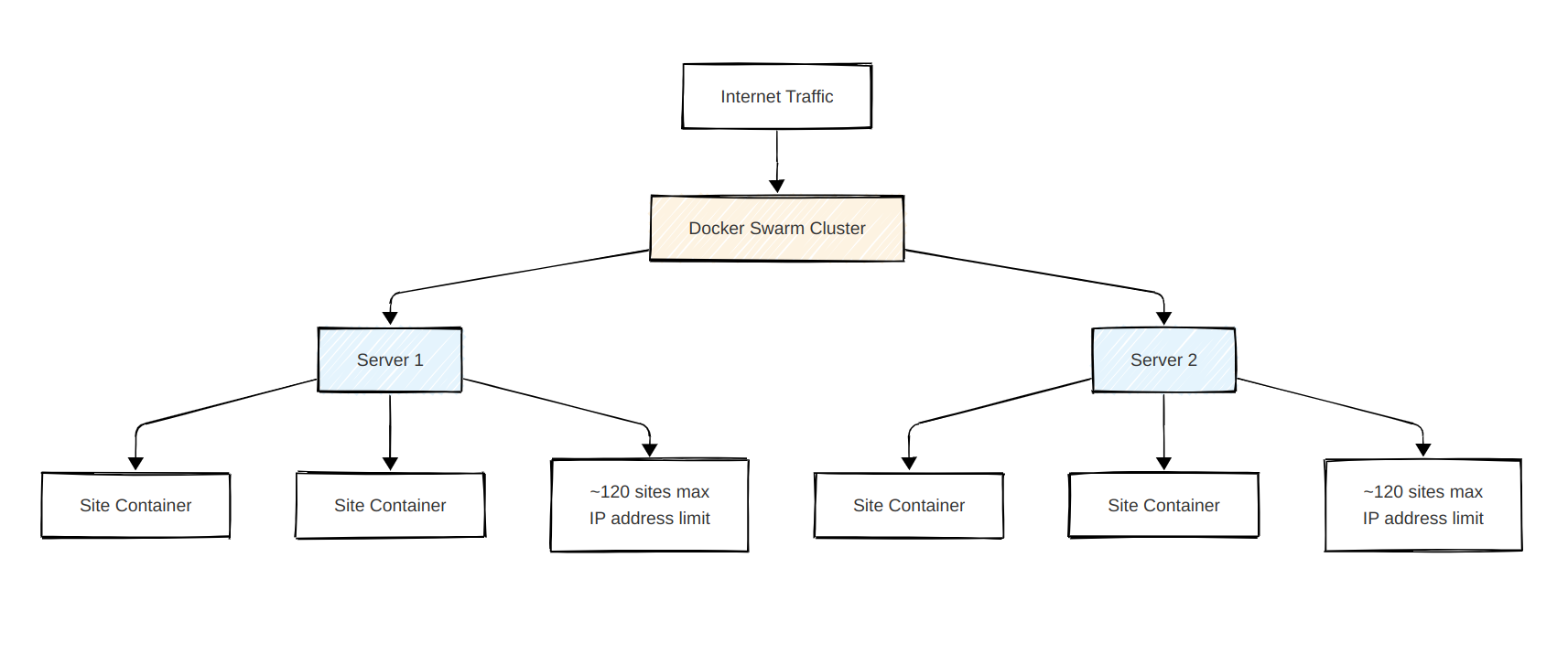
But, there was one big issue: Docker Swarm had a quirky limitation on how many internal network addresses it could assign per server. With each site needing a couple of these (for different containers), it meant I could only host about 120 sites per server, even if the server had plenty of processing power and memory left.
That sucked. The servers were massively oversized for that. A fully "loaded" server ran at about 40% RAM usage.
After a few months running everything on Docker Swarm (and fighting its standards, which are not made for high container density – e.g. running Ghost sites on scale), I decided to pull the plug: Kubernetes.
Kubernetes
Kubernetes has always been this scary monster for me. Expensive, over-engineered, complicated. That's what others always told me. However, my first couple of experiments with Kubernetes gave me a completely different picture.
It felt like it had all the advantages from Docker Swarm (automatic scheduling on different servers, self-healing) in a more mature environment. It took me a few weeks, but finally, I had an environment that I could test in production. I moved all my internal sites (the Magic Pages website, this blog, the theme demo pages, and some sites from friends and family) to the new Kubernetes cluster and let it run for a couple of weeks before I migrated the rest (by hand).
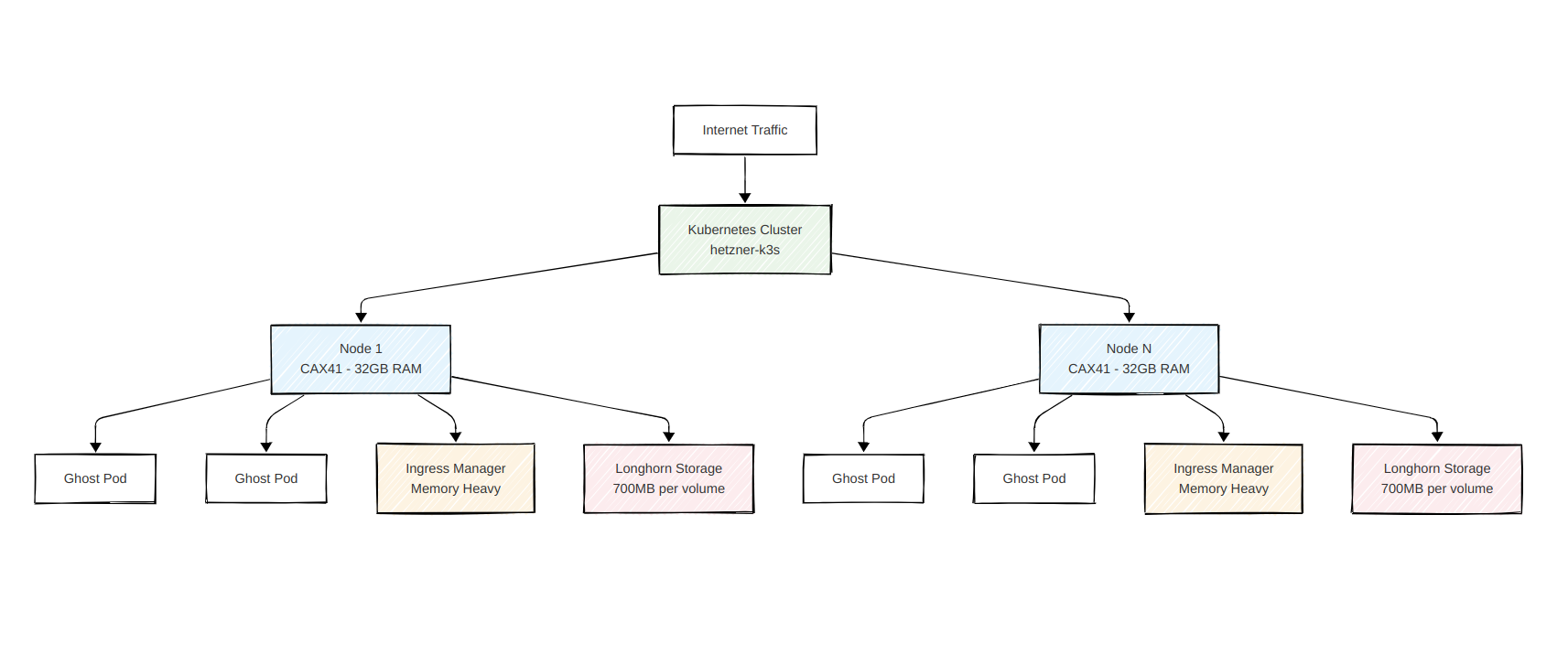
That was around a year ago. And frankly, moving everything to Kubernetes was the best decision I could have made for Magic Pages at that time.
I used a tool called hetzner-k3s for the infrastructure management:
This made everything super smooth and allowed me to scale Magic Pages from around 100 sites to over 600 within a year. The perfect foundation for a self-sustaining business.
However, not everything is perfect. And that's where we are now – and why I am writing this post (which is the first part of a series).
The Problems
Kubernetes fulfilled on its promise to self-heal and distribute workloads among different servers. But it also comes with a price. The price is monetary, but also time. Right now, I am spending about 75% of my "Magic Pages time" on managing the infrastructure – because something is always going wrong.
Nothing major – but from autoscaling configurations to storage pools or networking issues, I have seen it all in the last half a year or so. The solution is usually pretty simple: add more server resources 🙃
One example: all Ghost sites have storage volumes attached, that store the content folders (themes, images, file uploads, etc.). A few months ago I moved this from a single NFS server to a more Kubernetes-native storage solution called Longhorn. And hey, I wrote a whole post on here about it:

Looking back, it delivered on everything I hoped for. But it comes with a price tag I didn't consider: memory.
Longhorn creates multiple replicas of storage volumes on different servers, in order to prevent a disaster scenario, where a server goes down and all data is lost. That's great!
However, it is super memory-intense. Key components of Longhorn, which manage the storage replicas, turned out to be surprisingly hungry for memory – consuming a very large portion of the available resources on the nodes where they ran, and significantly impacting the overall memory usage of the cluster. I have already optimised it, but it's not changing much.
For perspective, the average Ghost site on Magic Pages uses about 300 MB of memory. The average Longhorn manager component (related to each storage volume) uses about 700 MB of memory.
Similarly, the components responsible for routing incoming internet traffic to the correct Ghost site (my ingress managers) also started consuming more and more memory as I added more sites.
Both of these wouldn't be issues on its own. But combined with the Kubernetes setup on Hetzner, it becomes a bit of a problem. Over the last 7 months (basically the biggest growth here at Magic Pages) the cost per site has increased by 300%, just because I had to add more resources for memory-hungry processes (that were not Ghost...).
The problem: Hetzner Cloud instances only scale to a certain level. 32GB of memory. That was a sweetspot a year ago, but becomes inefficient by now. I basically have lots of small servers running – but it would be more efficient to have fewer bigger servers, so they have enough resource buffers. Right now, these buffers exist, but since the servers are so small to begin with, it means I can fit fewer sites on a single server, and have to order more and more.
When I ran an analysis on this last week, my first thought was to just change the storage engine, since Longhorn uses so much memory (that's effectively the issue). However, it then also triggered another thought: wouldn't it be better to have a managed control plane for Magic Pages' Kubernetes cluster?
And then the rabbit hole began.
I researched and researched. Ran calculation after calculation. The conclusion: a managed Kubernetes cluster would make Magic Pages prohibitively expensive. In the cheapest case, my cost would 5x over night. Yikes.
My next thought: is it possible to have a managed control plane on Hetzner? Maybe with dedicated bare metal servers, to solve both issues (memory/container density and managed control plane)?
Short answer: yes, but cost.
There are providers that manage the control plane for you. While the cost was less than fully managed Kubernetes clusters on other cloud providers, they would still 2-3x my running cost.
So, I guess I am stuck? Just change the storage provider underneath? That was the sad conclusion of an evening of research and tinkering.
The next day I woke up, had a shower – and experienced this weird shower effect. You know, when there are no outside influences, you're just there with your thoughts.
"Let's take a step back. What if Kubernetes is not the correct answer to my question?"
It opened up an explosion of thoughts. I realised that every iteration of Magic Pages' infrastructure was done out of the necessity to solve a problem. Docker Swarm was used because my first server didn't have enough capacity anymore. Kubernetes then replaced Docker Swarm, because I was just fighting the Docker Swarm environment. Both of these switches were problem oriented. Not solution oriented.
And when I changed that mindset, I began to see a bit clearer.
Instead of hastily jumping into "the next best thing", I took a moment. While my customers thankfully haven't felt these growing pains directly in terms of site performance or reliability, the current setup is impacting Magic Pages. It's consuming a huge chunk of my time for reactive management, and it's making my infrastructure less efficient and more costly per site as I scale. This isn't a sustainable path if I want to keep offering great value, personal service, and continue to innovate in the sphere of managed Ghost hosting.
For the last week, I am now researching like crazy. I created a few guard rails that any new solution must have:
- High availability built in.
- Replicated storage.
- The ability to move sites between servers without downtime (live migration) for maintenance, and automatic rescheduling of sites if a server unexpectedly fails.
- Dedicated servers should be used for efficient resource use (since huge dedicated servers always give you better value for money compared to smaller cloud instances).
- Purely open source and self-hosted.
- Can be scaled easily.
- No quick solutions. All implementations must be based on best practices.
I want to share my progress here on this blog over the next few weeks. The goal is simple: rather than simply reacting to issues, I want to design a hosting infrastructure that is built on proven principles. Whether that will be Kubernetes, Docker, or something completely different is still up in the air.